An enterprise-grade, no-code platform with connectors, workflows, forms, analytics, AI/ML, visualizations, dashboards, web & mobile apps, and custom reports.
Simplify your digital transformation today and streamline your business, cut costs, and boost efficiency
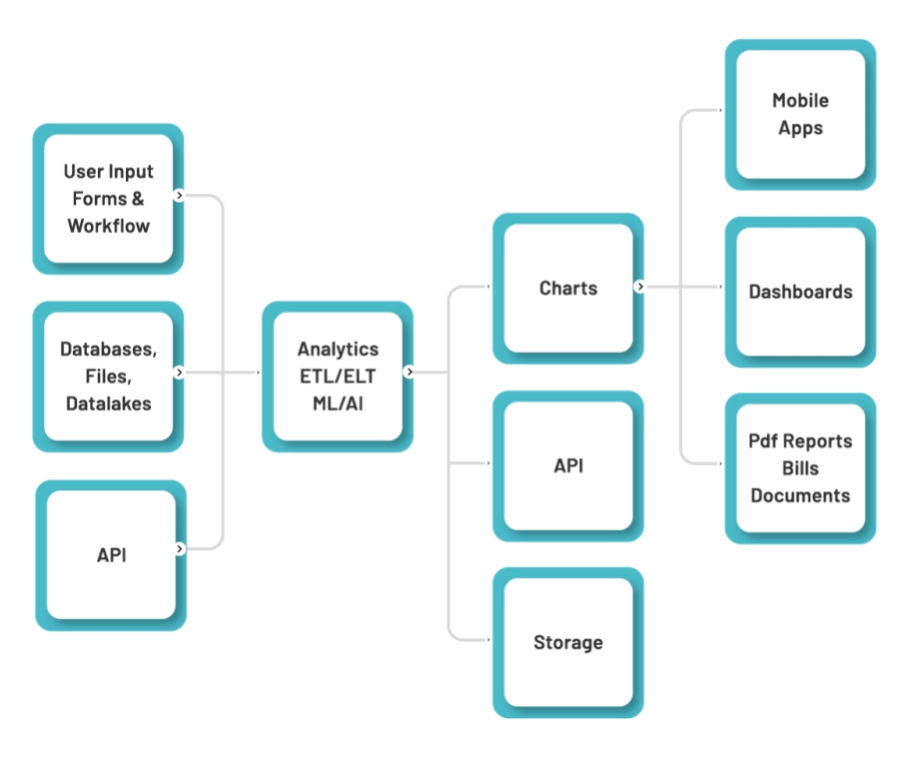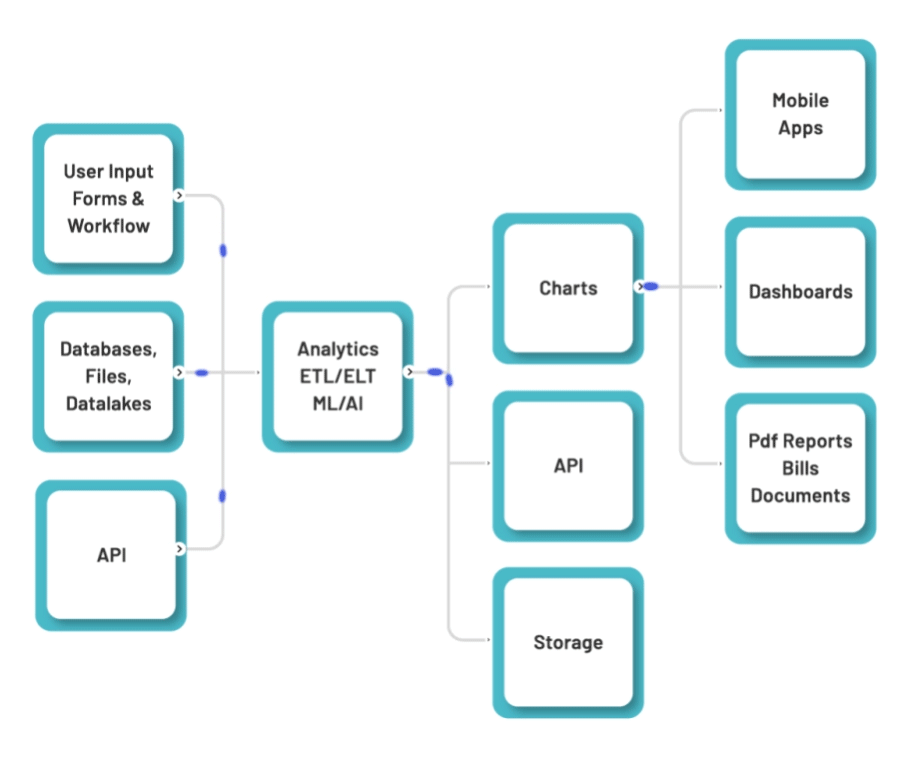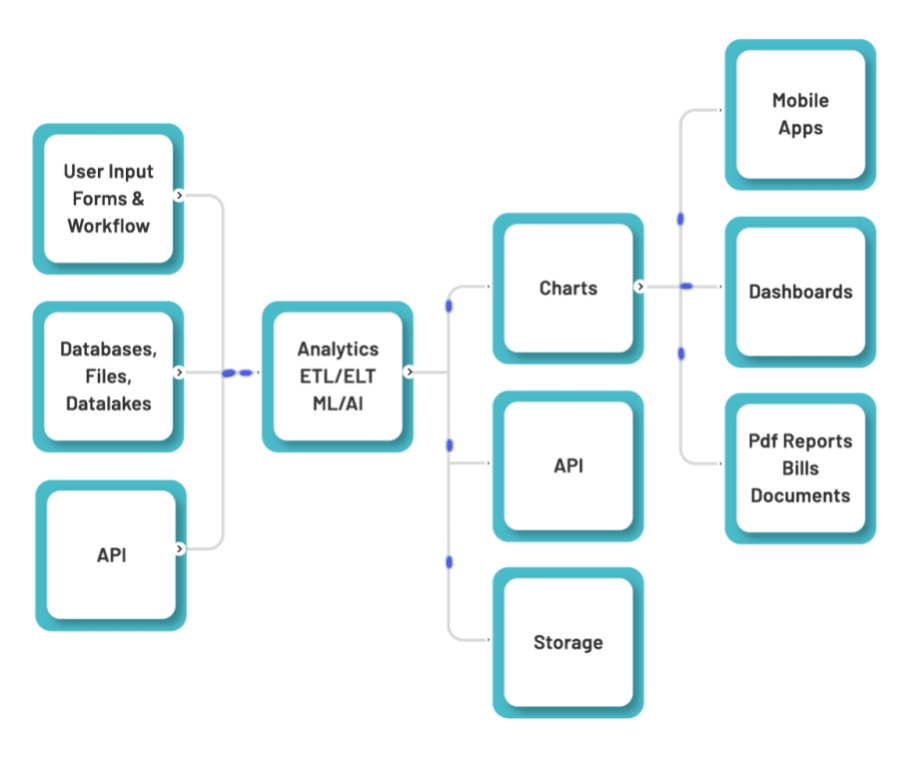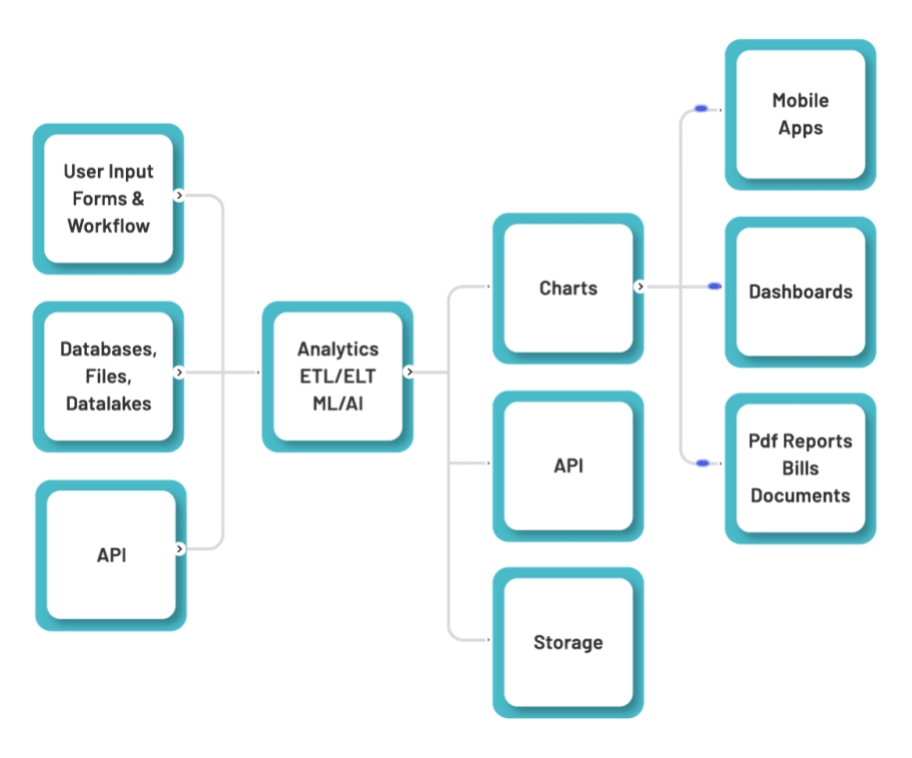

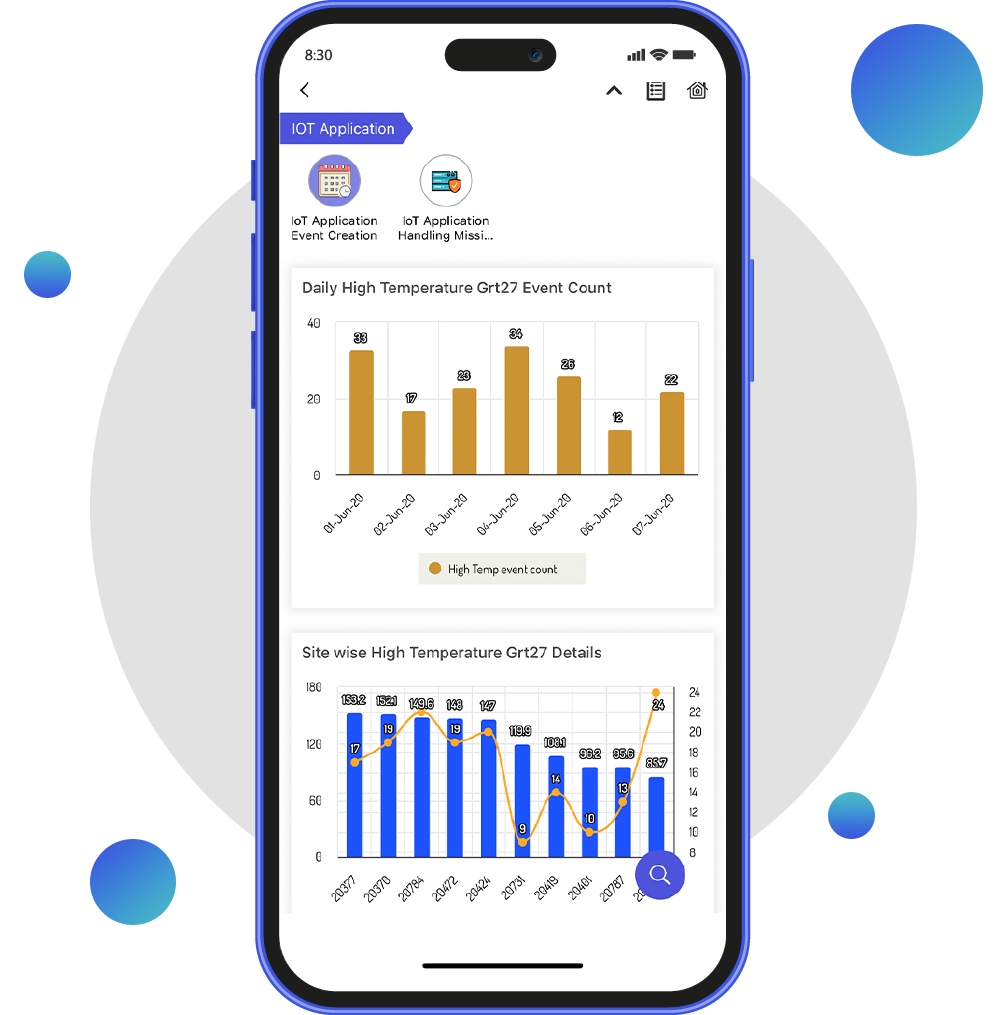
Unlock the power of AI integration with Pirl, the ultimate no-code platform that connects seamlessly to any external AI engine via our REST API engine. Leverage the insights derived from AI to supercharge your applications with minimal effort.
Pirl simplifies the most time-consuming part of AI and ML development—data preparation. With an intuitive drag-and-drop interface, you can effortlessly collect, clean, and curate data, setting the stage for the ML engine to deliver impactful results.
AI and ML are only valuable when integrated into real-world business applications. Pirl makes it easy to incorporate powerful AI and ML insights directly into your business processes, enabling smarter decisions and streamlined workflows without writing a single line of code.
AI and ML are constantly evolving, and staying ahead of the curve is key. Pirl's modular approach ensures that as the field advances, you can easily swap out AI/ML engines without disrupting your existing applications, keeping your business agile and future-ready.
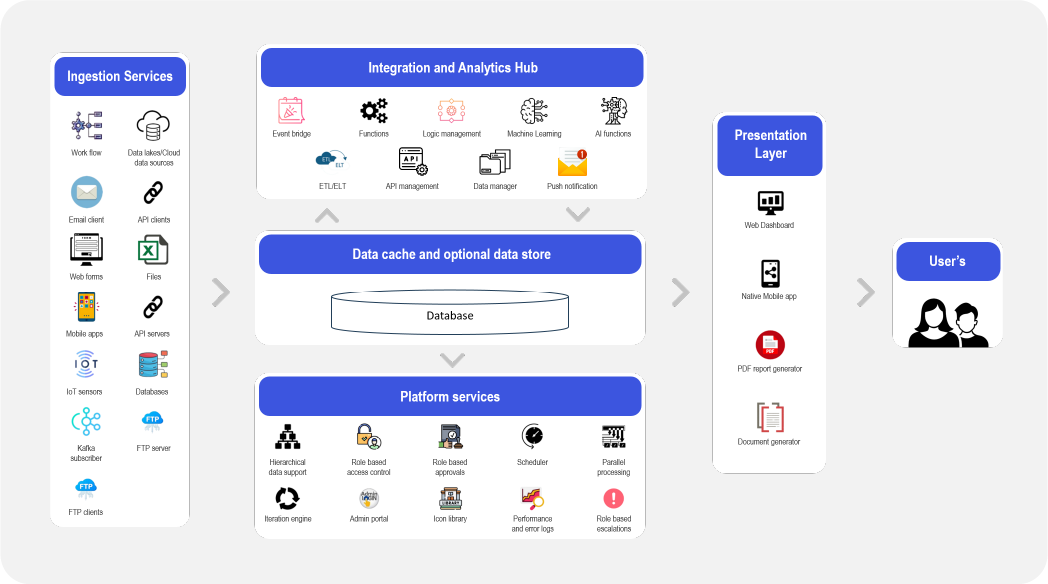
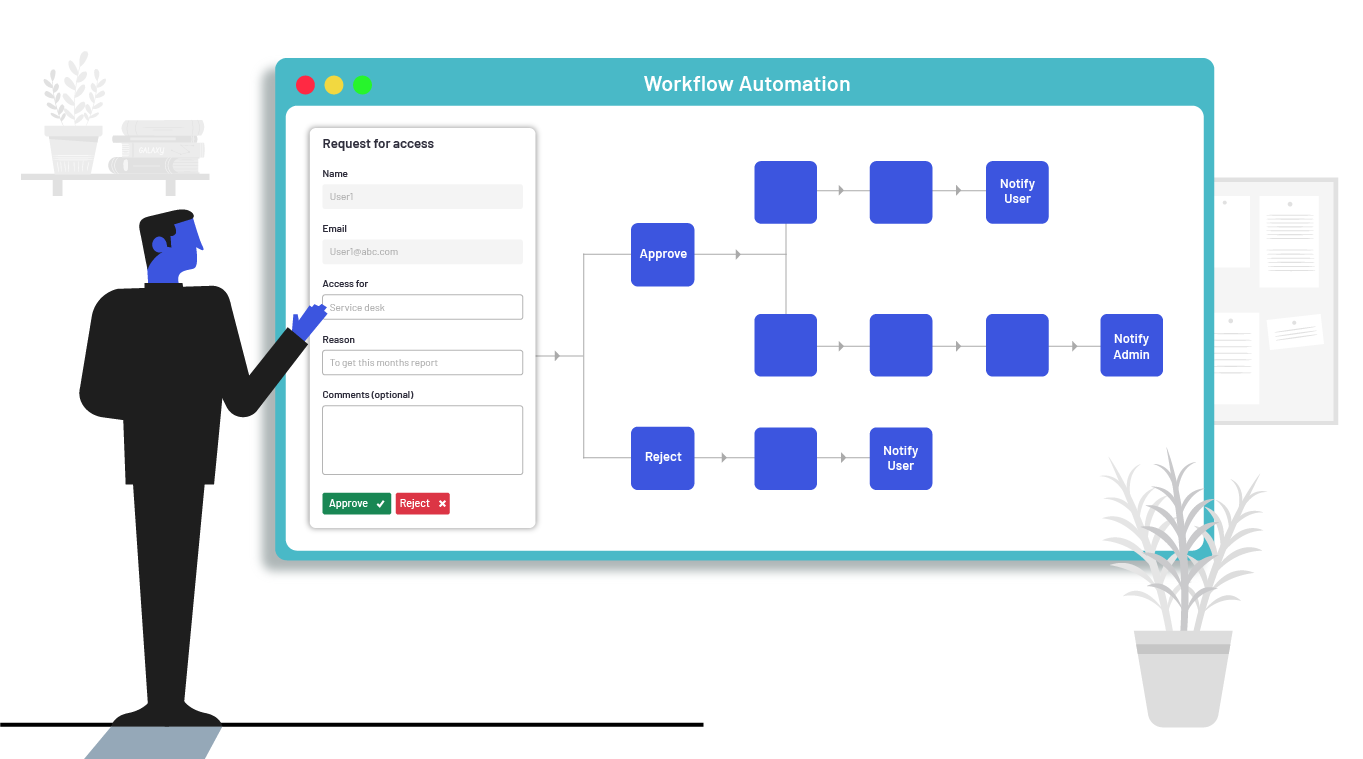
Ready to see Pirl in action? Schedule a personalized demo with one of our experts and discover how our solutions can transform your business.
Copyright 2024 © All Right Reserved by PIRLLABS Pvt Ltd